
Így lett Starcraft II nagymester AlphaStar, a mesterséges intelligencia
A Google AI kutatóintézetének fejlesztése komplex tanulási módszerekkel jutott be a legjobb játékosok körébe.
0
A Google AI kutatóintézetének fejlesztése komplex tanulási módszerekkel jutott be a legjobb játékosok körébe.
A Google AI kutatóintézetének fejlesztése komplex tanulási módszerekkel jutott be a legjobb játékosok körébe.
A mai mesterséges intelligencia már messze áll attól, hogy programozók raknak össze parancssorokat, „ha ez történik, csináld ezt” megoldásokkal. Ma már ezek a szoftverek képesek tanulni, önmagukat fejleszteni – sok próbálkozás alapján eldönteni, mi a jó stratégia, és arra építeni.
A gépi tanulás rövid története
Az ilyen jellegű tanulási módszereket sok probléma megoldására be lehet tanítani, de a fejlesztők egyik kedvelt célpontjai a relatíve egyszerű szabályrendszerű társasjátékok. 1992-ben az IBM fejlesztői megalkották a TD-Gammon-t, ami már képes volt a visszacsatolásokra épülő tanulás elvén megtanulni elverni a legjobb backgammon játékosokat.
Ehhez azonban még egy áttörésre szükség volt: az úgynevezett „ön-játék” volt a legnagyobb ötlet, ami forradalmasította a technikát. Ennek során a szoftver önmaga korábbi verziói ellen játszott, így saját magán tanulhatta meg a játékot. Az új módszerrel a rendszer gyorsabban tudott haladni, és képes volt emberfeletti képességet szerezni a játékokban. Ezzel a technológiával született meg a Google AI kutatóintézetének, a Deepmind laboratóriumában a legnagyobb Go mestereket is legyőző AlphaGo és hasonló társai.

Az AlphaGo küzdelme a legjobb játékosok ellen | Kép forrása: The Verge
A következő lépés az volt, hogy megpróbáljanak eggyel komplexebb játékok leküzdésére is kísérletet tenni. A Deepmind fejlesztőinek választása a StarCraft II-re esett. Az ingyenesen elérhető RTS-ben sokkal sokrétűbb stratégiapaletta kidolgozására nyílik lehetőség, az egy időben meghozható lehetséges döntések száma pedig nagyságrendekkel magasabb, mint a sakkban vagy a Góban. Az új játék azonban új kihívásokat is állított a tanuló rendszer elé.
Kő-papír-olló, avagy az ördögi kör
A tanulórendszerek egyik nagy kihívása a felejtés. A rendszer ugyanis bizonyos helyzetekben olyan ördögi körökbe keveredhet, ahol „elfelejtheti”, mik a hatékony stratégiák, és egy helyben toporog, miközben azt gondolja, hogy fejlődik.
Ezt a problémát a legjobban a kő-papír-olló játék alapján lehet megérteni. Tegyük fel, hogy a szoftver épp azt gondolja, hogy a kő használata a legjobb stratégia. Erre az ellenfele hamar kidolgozza a papír stratégiáját, hiszen ez veri a követ. Miután rájött, hogy a papír a felsőbbrendű stratégia, az ellenfelek az ollót kezdik el használni, és ez lesz az „új meta”. Így tovább körbe-körbe, a rendszer folyton azt gondolja, hogy minden egyes alkalommal egyel jobb stratégiára talált – mindeközben „elfelejtve”, hogy erre már egyszer rájött.
Tekintve, hogy a StarCraft II legtöbb egysége a kő-papír-ollóhoz hasonló stratégiákban működik egymás ellen (lásd a Void Ray – Stalker – Immortal hármast például), az analógia itt különösen jól működik. Ezt a fajta túlspecializációt és felejtést kellett tehát valahogy kiküszöbölnie a fejlesztőknek, ha igazán sikeres játékost akartak faragni a szoftverből.

Kép forrása: nargaque.com
Edzőpartnerek
Amikor az ember fejlődni szeretne valamiben, időnként társakat kér meg arra, hogy segítsenek neki: vegyék észre a hiányosságaikat, és kényszerítsék rá arra, hogy azokban fejlődjön. Hasonló technológiát alkalmaztak a Deepmindnál is – ligákban versenyeztették egymás ellen a szoftver különböző változatait, ahol majdnem mindenki célja az volt, hogy ő legyen a legjobb.
Emellett azonban olyan ellenfeleket is indítottak a szoftver fő tanuló ága ellen, akiknek nem az volt a céljuk, hogy ők is nyerjenek, hiszen ezzel csak az ördögi kört erősítették volna. Ehelyett a változatok célja az volt, hogy specifikus hiányosságokat találjanak a szoftver stratégiájában, majd kihasználják azokat.
Így például, ha az AlphaStar elkezdett túlságosan egy egységre fókuszálni, az ezt kihasználó társak annak counterét küldték ellene. Így a szoftver újabb lehetséges stratégiákat tudott kidolgozni, és egyre komplexebb szituációkra is kidolgozhatott válaszokat.
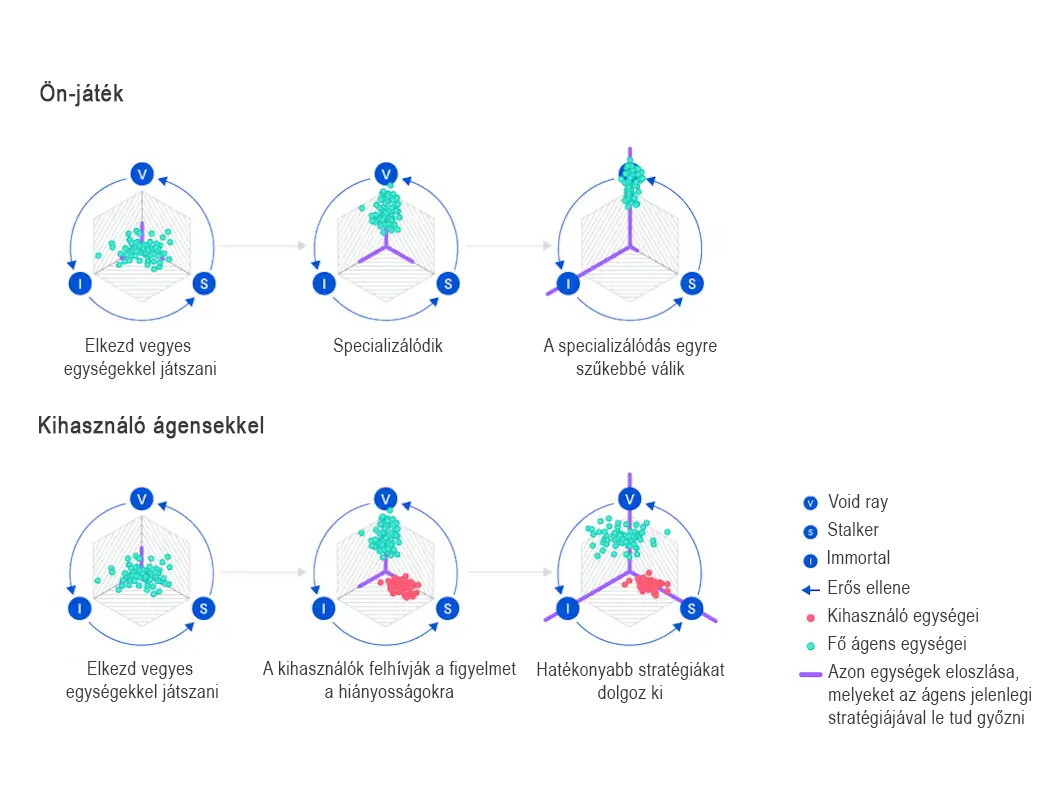
Kép forrása: Deepmind
Út a nagymester ligába
Az AlphaStar mindezekre építve idén januárban kihívta, majd le is győzte a StarCraft II egyik profi játékosát, a Team Liquid-es Grzegorz „MaNa” Kominczot, ám az egyszeri győzelem még nem igazolta a szoftver valós győzelmét az emberi játékosok felett. Az új cél a Grandmaster cím elérése lett.
Ehhez a rendszert különböző korlátozások alá kellett vetni, hogy a Battle.net szabályainak megfelelően kerülhessen a ligába. Így például az AlphaStar az emberi játékosokhoz hasonlóan csak egy kamerán keresztül láthatja a meccseket, és limitálva van a cselekvéseinek frekvenciája is (hogy az emberi fizikai képességekhez hasonló mennyiségű kattintást/billentyűlenyomást végezhessen másodpercenként).
Mindezen korlátozások mellett, az eddig ecsetelt tanulási metódusokat alkalmazva szépen lassan addig kúszott felfelé a szoftver a ranglistán, míg képes volt bekerülni a játékosok rangsorolásának legmagasabb, Grandmaster kategóriájába.
A Panda Global egyik játékosa, Diego „Kelazhur” Schwimer így nyilatkozott az AlphaStar elleni játék élményéről:
„érdekes és szokatlan játékos – a sebessége és a reflexei mint a profiké, de a stratégiái és a stílusa teljesen egyedi. A képzésének a módja, az egyes változatok ligában való versenyeztetése elképzelhetetlenül szokatlan játékmenetet eredményezett. Megkérdőjelezed miatta, hogy a profi játékosok mennyire is használták ki a StarCraft-ban rejlő lehetőségeket valójában.”
A fejlesztés egyelőre nem áll meg. Az AlphaStar célja nem az volt, hogy „megoldják” a StarCraft II problémáját. A játék egy jó lehetőség volt arra, hogy egy olyan szoftvert fejlesszenek, mely képes tanulni és fejlődni egy olyan területen, ahol kevés információ alapján gyorsan és átgondoltan kell döntéseket hozni a másodperc töredéke alatt. A projekt során megtanulták hogyan lehet jól tanítani egy gépet önjáték és hozzáértők tanácsai alapján.
Később az itt tanult dolgokat át lehet ültetni más területekre, ahol hasonló feltételek egyelőre lehetetlenné teszik, hogy a gépek felvegyék a versenyt az emberekkel.

